
Stata19破解版为用户提供了一整套的数据分析、数据管理以及绘制专业图表的解决方案,你可以在Stata中完成的一些基本任务,例如打开数据集,调查数据集的内容,使用一些描述性统计信息,制作一些图表以及执行一个简单的回归分析等等,它的功能超级的丰富,包含线性混合模型、均衡重复反复及多项式普罗比模式。用Stata绘制的统计图形相当精美,图形可直接被图形处理软件或文字处理软件(如Word等)调用。它操作灵活,简单,易学易用,是一款非常轻便的统计分析软件。由于在Stata软件中能便捷地实现多种先进统计方法,越来越受到用户的推崇,并和SAS,SPSS一起被称为新的三大权威统计软件。非常适合统计、金融、经济、生物、医疗卫生保健、社会人文、心理学等多学科行业,软件的运算速度超级的快,操作方式超级的简单便捷,数据格式简单,分析结果输出简洁明快,易于阅读,这都使得Stata成为极其适用于统计教学的软件。本次带来破解版下载,有需要的朋友不要错过了!
软件特色
1、统计分析
Stata的统计功能很强,除了传统的统计分析方法外,还收集了近20年发展起来的新方法,如Cox比例风险回归,指数与Weibull回归,多类结果与有序结果的logistic回归,Poisson回归,负二项回归及广义负二项回归,随机效应模型等。
2、绘图功能
Stata提供了包含广泛图形库的一系列图形类型供用户使用。其中主要的图形类型有:直方图、扇形图、条形图、散点图、直线图以及数据拟合图。这些图形的绘制设计一个或两个变量,可以将它们分别称为一维或二维图形。Stata还提供了诸如盒形图、长钉图、圆点图、面积图以及其他各种常用于财经数据的图形。在二维图形中,有时多个图形可以进行叠加,这样,Stata最终会在同一个坐标内显示由多个命令分别绘制的不同的图形。在有些非绘图命令中,也提供了专门绘制某种图形的功能,如在生存分析中,提供了绘制生存曲线图,回归分析中提供了残差图等。
3、矩阵运算
矩阵代数是多元统计分析的重要工具, Stata提供了多元统计分析中所需的矩阵基本运算,如矩阵的加、积、逆、 Cholesky分解、 Kronecker内积等;还提供了一些高级运算,如特征根、特征向量、奇异值分解等;在执行完某些统计分析命令后,还提供了一些系统矩阵,如估计系数向量、估计系数的协方差矩阵等。
4、程序设计
Stata是一个统计分析软件,但它也具有很强的程序语言功能,这给用户提供了一个广阔的开发应用的天地,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。事实上,Stata的ado文件(高级统计部分)都是用Stata自己的语言编写的。
由于Stata在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,Stata也是采用命令行方式来操作,使用上简单,用Stata绘制的统计图形相当精美,很有特色。
新功能介绍
一、套索
1、所有预期的模型选择和预测工具
交叉验证
适合度
系数路径
结分析
套索和弹性网
2、除了尖端的推理方法
对变量选择的错误很有帮助
适当推断感兴趣的系数
双重选择,偏出和交叉拟合
3、连续,二元,计数结果
二、可重复的报告
使用Stata结果和图形创建Word,HTML,PDF和Excel文件。
PDF格式 字 HTML 高强
Stata的集成版本控制为您提供真正可重复的报告。想要动态文件?所有这些报告都可以随着数据的变化而更新。
三、Meta分析
使用Stata的新元分析套件,您可以轻松汇总多项研究的结果。
)估算整体效果大小
)执行随机效应,固定效应或共同效应元分析)在森林图中显示结果
)分析子组
)执行元回归
)探索小型学习效果
)评估发表偏倚
)执行累积荟萃分析
四、选择模型
借助Stata新的独特选择模型分析功能,您可以真实地解释您所选模型的结果。
预计会有多少旅客选择乘机旅行?
每增加1万美元的收入如何改变乘飞机旅行的可能性?机场等候时间增加30分钟。这对空中旅行的可能性有何影响?乘火车?坐巴士?坐车?
五、Python集成
使用Stata中的任何Python包
)Matplotib用于三维图形
)Scrapy用于抓取数据
)TensorFlow用于机器学习学到更多,
六、贝叶斯分析的新内容
多个链条、Gelman-Rubin收敛诊断、贝叶斯预测、后验预测p值
七、面板数据ERM内生性+
选择+治疗+
面板数据
同时处理所有这些并发症。
八、从中导入数据
SAS、SPSS
九、非参数序列回归
关于功能形式的不可知论者?泊松或负二项式?协变量的立方或二次方?
没问题。
使用非参数回归,您可以探索响应面,估计总体平均效应,执行测试并获得置信区间。
十、帧-内存中的多个数据集
将数据集同时加载到帧中。
链接相关的帧。
得心应手。
将结果记录在另一帧中。
使代码运行得更快。
十一、Cl的样本大小分析
需要多少个主题才能达到所需宽度的置信区间?
为Cl执行样本量分析
)一个意思是
)一个方差
)两个独立的手段
)两个配对的手段
)你自己的方法
十二、面板数据混合logit
你每天都选择晚餐。
您每年都会选择汽车保险。你选择每年夏天去哪里度假。
现在,您可以在这些决策中考虑您的情况。
十三、非线性动态随机一般均衡(DSGE)模型
现在您可以将线性化留给我们。
指定您的非线性模型并评估政策含义
)解决)估计
)校准)图形
十四、多组IRT
1、适合多组IRT模型
)用于二元结果的1PL,2PL和3PL模型)序数结果的分级响应,部分信用和评级量表模型)分类结果的名义响应模型
2、比较各组的估算值
)物品难度)物品歧视
3、图组差异
)ICC,TCC,IF,TIF
4、执行差异项功能的基于模型的测试
十五、xtheckman如果你知道这意味着什么……
.…..你知道你想要它。
十六、非线性混合效应模型,具有滞后,线索和差异
多剂量药代动力学模型
成长模式
更多
十七、Heteroskedastic命令probit
受试者或群体之间差异的模型差异
十八、图形的磅值
现在使用打印机点,厘米或英寸指定文本,标记,边距,线条等的大小。
软件功能
1、线性模型
回归•审查结果•内生回归量•自举,折刀,鲁棒和群集稳健方差•工具变量•三阶段最小二乘•约束•分位数回归•GLS•更多
2、小组/纵向数据
具有强大标准误差的随机和固定效应•线性混合模型•随机效应概率•GEE•随机和固定效应泊松•动态面板数据模型•工具变量•面板单位根测试•更多
3、多级混合效果模型
连续,二元,计数和生存结果•两级,三级和更高级模型•广义线性模型•非线性模型•随机截距•随机斜率•交叉随机效应•效果和拟合值的BLUP•分层模型•残差错误结构•DDF调整•支持调查数据•更多
4、二进制,计数和有限的结果
logistic,probit,tobit•泊松和负二项•条件,多项,嵌套,有序,秩序和刻板逻辑•多项概率•零膨胀和左截断计数模型•选择模型•边际效应•更多
5、选择模型
离散选择•等级排序备选方案•条件logit•多项式probit•嵌套logit•混合logit•面板数据•特定于案例和特定于备选方案的预测器•解释结果预期概率,协变量效应,跨备选方案的比较•更多
6、扩展回归模型(ERM)
内源性协变量•样本选择•非随机处理•小组数据•单独或组合出现问题•连续,区间删失,二元和有序结果•更多
7、广义线性模型(GLM)
十个链接函数•用户定义的链接•七个分布•ML和IRLS估计•九个方差估计•七个残差•更多
8、有限混合模型(FMM)
fmm:17个估算器的前缀•单个估算器的混合•混合多个估算器或分布的混合•连续,二元,计数,序数,分类,删失,截断和生存结果•更多
9、空间自回归模型
因变量,自变量和自回归误差的空间滞后•面板数据中的固定和随机效应•内生协变量•分析溢出效应•更多
10、ANOVA / MANOVA
平衡和不平衡设计•阶乘,嵌套和混合设计•重复测量•边际均值•对比•更多
11、确切的统计数据
精确逻辑和泊松回归•精确的病例对照统计•二项式检验•Fisher精确检验r×c表•更多
12、流行病学
标准化率•病例对照•队列•匹配病例对照•Mantel-Haenszel•药代动力学•ROC分析•ICD-10•更多
13、DSGE模型
以代数方式指定模型•求解模型•估计参数•识别诊断•策略和转换矩阵•IRF•动态预测•更多
14、测试,预测和效果
Wald检验•LR检验•线性和非线性组合•预测和广义预测•边际均值•最小二乘均值•调整均值•边际和部分效应•预测模型•Hausman检验•更多
15、对比,成对比较和边距
比较均值,截距或斜率•与参考类别,相邻类别,宏均值等进行比较。•正交多项式•多重比较调整•图形估计均值和对比•交互图•更多
16、重采样和模拟方法
bootstrap•jackknife•蒙特卡罗模拟•置换测试•更多
17、时间序列
ARIMA•ARFIMA•ARCH / GARCH•VAR•VECM•多变量GARCH•未观测组件模型•动态因子•状态空间模型•马尔可夫切换模型•商业日历•结构中断测试•阈值回归•预测•脉冲响应函数•单位根测试•过滤器和平滑器•滚动和递归估计•更多
18、生存分析
Kaplan-Meier和Nelson-Aalen估计,•Cox回归(脆弱)•参数模型(脆弱,随机效应)•竞争风险•危害•时变协变量•左,右和间隔审查•Weibull,指数,和Gompertz模型•更多
19、贝叶斯分析
数千种内置模型•单变量和多变量模型•线性和非线性模型•多级模型•连续,二进制,序数和计数结果•贝叶斯:46个估计命令的前缀•连续单变量,多变量和离散先验•添加自己的模型模型•多链•收敛诊断•后验总结•假设检验•模型拟合•模型比较•预测•更多
20、Meta分析
影响大小•常见,固定和随机影响•森林,漏斗和更多情节•亚组和累积分析•元回归•小研究影响•发表偏倚•更多
21、功率,精度和样本量
功效•样本量•效应量•最小可检测效果•CI宽度•平均值•比例•方差•相关性•方差分析•回归•群集随机设计•病例对照研究•队列研究•列联表•生存分析•平衡或不平衡设计•表格或图表中的结果•更多
22、治疗效果/因果推断
反向概率权重(IPW)•双重稳健方法•倾向得分匹配•回归调整•协变量匹配•多级治疗•内源性治疗•平均治疗效果(ATEs)•治疗后ATEs(ATETs)•潜在 - 结果均值(POMs) •连续,二元,计数,分数和生存结果•面板数据•更多
23、套索
套索•弹性网•模型选择•预测•推理•连续,二元和计数结果•交叉验证•自适应套索•双重选择•偏离•交叉拟合偏差•双机学习•内生协变•更多
24、SEM(结构方程模型)
图形路径图构建器•标准化和非标准化估计•修改指数•直接和间接影响•连续,二元,计数,序数和生存结果•多级模型•随机斜率和截距•因子分数,经验贝叶斯和其他预测•组和不变性测试•拟合优度•通过FIML处理MAR数据•相关数据•调查数据•更多
25、潜类分析
二元,序数,连续,计数,分类,分数和生存项目•为模型类成员添加协变量•与SEM路径模型相结合•预期类别比例•拟合度•类成员预测•更多
26、多重插补
9个单变量插补方法•多元正态插补•链式方程•探索缺失模式•管理插补数据集•拟合模型和池结果•变换参数•参数估计的联合测试•预测•更多
27、调查方法
多阶段设计•bootstrap,BRR,折刀,线性化和SDR方差估计•后分层•耙•校准•DEFF•预测余量•平均值,比例,比率,总数•汇总表•几乎所有估算器都支持•更多
28、聚类分析
层次聚类•kmeans和kmedian非层次聚类•树形图•停止规则•用户可扩展分析•更多
29、IRT(项目反应理论)
二元(1PL,2PL,3PL),序数和分类响应模型•项目特征曲线•测试特征曲线•项目信息功能•测试信息功能•多组模型•差异项功能(DIF)•更多
30、多变量方法
因子分析•主成分•判别分析•旋转•多维尺度•Procrustean分析•对应分析•双图•树状图•用户可扩展分析•更多
31、数据争论
数据转换•数据框•匹配合并•导入/导出数据•ODBC•SQL•Unicode•分组处理•附加文件•排序•行 - 列转置•标记•保存结果•更多
32、报告
可重现的报告•Word•Excel•PDF•HTML•动态文档•Markdown•Stata结果和图形•SVG•EPS•PNG•TIF•格式化文本和表格•更多
33、图像
线条•条形区域•区域•轮廓•置信区间•交互图•生存图•出版质量•定制任何内容•图形编辑器•更多
34、编程功能
添加新命令•脚本•面向对象编程•菜单和对话框编程•动态文档•Markdown•项目经理•Python集成•Java插件•C / C ++插件•更多
35、Mata-Stata严谨的编程语言
交互式会话•大规模开发项目•优化•矩阵求逆•分解•特征值和特征向量•LAPACK引擎•实数和复数•字符串矩阵•与Stata数据集和矩阵的接口•数值导数•面向对象编程•更多
36、图形用户界面
所有功能的菜单和对话框•数据编辑器•变量管理器•图形编辑器•项目管理器•文件编辑器•剪贴板预览工具•多个首选项集•更多
37、文档
31本手册•15,000多页•无缝导航•数千个工作示例•快速入门•方法和公式•参考•更多
38、基本统计
摘要•交叉表•相关性•z和t检验•方差检验•比例检验•置信区间•因子变量•更多
39、非参数方法
非参数回归•Wilcoxon-Mann-Whitney,Wilcoxon签署等级,Kruskal-Wallis测试•Spearman和Kendall相关性•Kolmogorov-Smirnov测试•精确二项CI•生存数据•ROC分析•平滑•自举•更多
40、GMM和非线性回归
广义矩量法(GMM)•非线性回归•更多
41、简单的最大可能性
使用简单表达式指定可能性•无需编程•调查数据•标准,稳健,自举和重叠SE•矩阵估算器•更多
42、可编程最大似然
用户指定的功能•NR,DFP,BFGS,BHHH•OIM,OPG,强大,bootstrap和jackknife SE•Wald测试•调查数据•数字或分析衍生产品•更多
43、其他统计方
kappa衡量interrater协议•Cronbach的alpha•逐步回归•正常性测试•更多
44、功能
统计•随机数•数学•字符串•日期和时间•正则表达式•Unicode•更多
45、互联网功能
能够安装新命令•网络更新•网络文件共享•最新的Stata新闻•更多
46、社区贡献的命令
搜索和下载数以千计的免费添加内容•发现Stata期刊中的新功能•通过发布到SSC共享命令•讨论Statalist上的社区贡献命令•更多
47、无障碍
第508条规定,残疾人无障碍
48、示例会话
适用于Mac,Unix或Windows的Stata示例会话。
安装破解教程
1、在本站下载并解压,得到SetupStata18.exe安装程序和破解文件夹
2、双击SetupStata18.exe运行,如图所示,勾选我接受许可证协议条款,点击next
2、双击SetupStata18.exe运行,如图所示,勾选我接受许可证协议条款,点击next
3、勾选与您的许可证匹配的类型,勾选StataSE,点击next
4、选择软件安装路径,点击next
5、继续安装,如图所示,点击finish
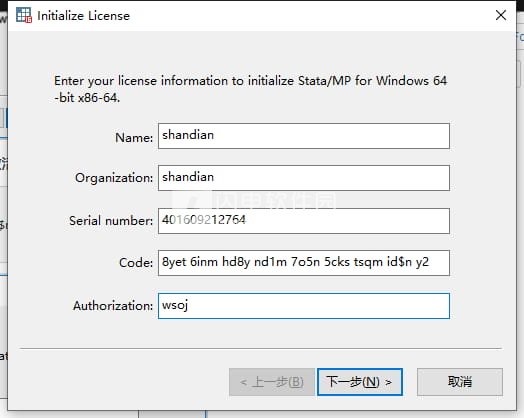
6、软件安装完成后,运行软件,如图所示,这里我们对应输入下面的激活信息激活软件,用户名和公司随意输入
serial number:401609212764
code:8yet 6inm hd8y nd1m 7o5n 5cks tsqm id$n y2
Authorization:wsoj
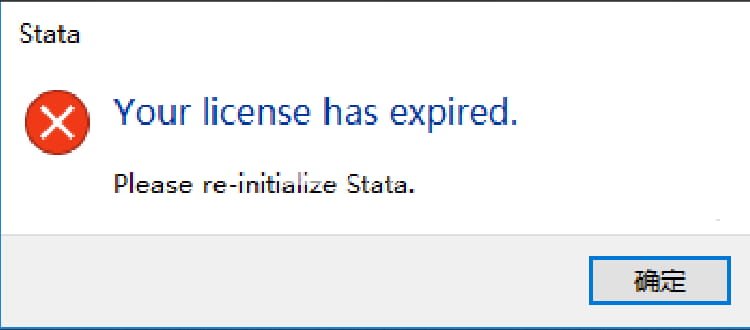
7、点击下一步后,如图所示,软件会提示许可已过期,无需理会,直接退出即可
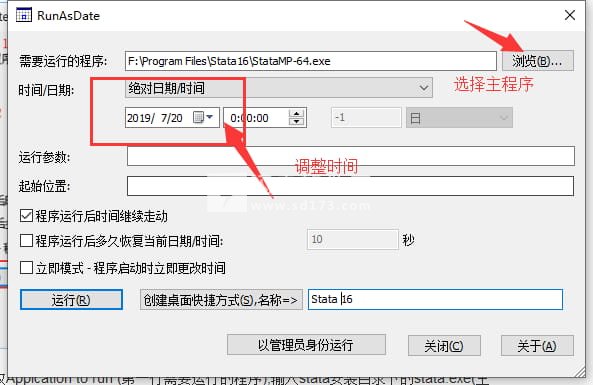
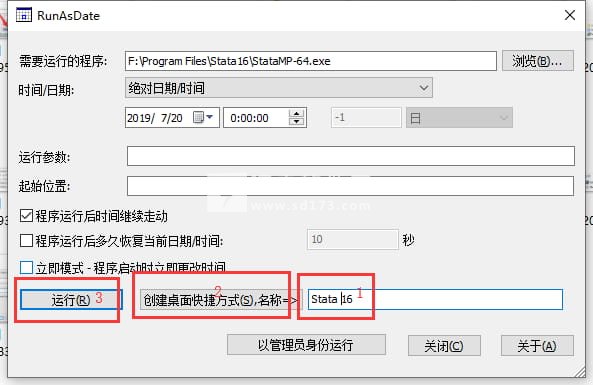
8、现在我们回到安装文件夹中,将runasdate文件夹复制到软件安装目录中,然后我们运行runasdate,如图所示,我们修改时间,首先点击浏览选择安装目录下的主程序,然后将时间进行如下调整
9、在下面,根据顺序,如图所示,创建快捷方式,点击运行
10、以上即可完美安装,安装完后即可修改系统时间到正常时间即可,以后使用不再需要修改时间。
11、最后需要注意的是,我们运行软件的时候,要使用刚才我们生成的快捷方式,不要使用原始的快捷图标。
使用说明
1、简单的数据管理
通过在数据编辑器中浏览数据,我们可以快速了解数据。 这可以通过单击数据编辑器(浏览)按钮,或从菜单中选择数据>数据编辑器>数据编辑器(浏览)或键入命令browse来完成。
单击“数据编辑器”按钮时不会发出任何命令,因为打开数据编辑器不会影响数据集或任何可能的分析。
当“数据编辑器”窗口打开时,您可以看到Stata将数据视为一个矩形表。 对于所有Stata数据集都是如此。 列表示变量,而行表示观察。 变量具有一定的描述性名称,而观察结果则编号。
数据以多种颜色显示 - 乍一看,黑色列出的变量似乎是数字,而颜色中的变量是文本。这值得研究。单击make变量下的单元格:顶部的输入框显示汽车的品牌。向右滚动,直到看到外部变量。单击其中一个单元格。虽然单元格可能显示“国内”,但输入框显示0.这表明Stata可以将分类数据存储为数字,但显示人类可读的文本。这是由Stata称之为价值标签的。最后,在看起来是数字的rep78变量下,有一些单元格只包含一个点(。)。点对应于缺失值。
以这种方式查看数据虽然很舒服,但却没有提供有关数据集的信息。
我们可以获得有关数据是什么以及数据存储方式的更多详细信息。
单击关闭按钮关闭数据编辑器。
我们可以通过描述数据集的内容来查看数据集的结构。这可以通过转到数据>描述数据>描述内存中的数据或菜单中的文件并单击确定或在命令窗口中键入describe并按Enter键来完成。无论您选择哪种方法,都会得到相同的结果:
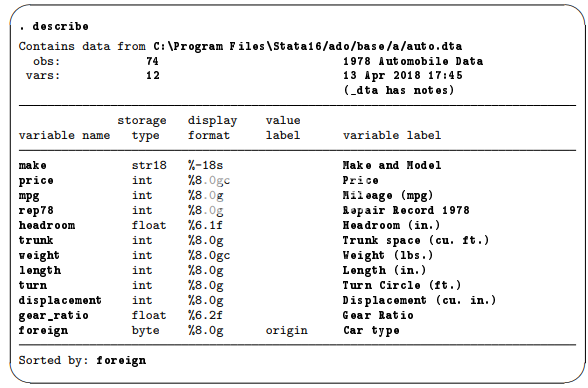
在列表的顶部,提供了有关数据集的一些信息,例如它存储在磁盘上的位置以及上次保存数据集的时间。 大胆的1978年汽车数据是数据集打开时出现的简短描述,被Stata称为数据标签。 phrase_dta有笔记告诉我们数据集附有注释。 我们可以通过在命令窗口中输入✗notes来查看有哪些注释:

在列表的顶部,提供了有关数据集的一些信息,例如它存储在磁盘上的位置以及上次保存数据集的时间。 大胆的1978年汽车数据是数据集打开时出现的简短描述,被Stata称为数据标签。 phrase_dta有笔记告诉我们数据集附有注释。 我们可以通过在命令窗口中输入✗notes来查看有哪些注释:
回顾描述中的列表,我们可以看到Stata不仅仅跟踪原始数据。每个变量都有以下内容:
·变量名称,在与Stata通信时称为变量。变量名称是Stata名称的一种类型。参见[U] 11.3命名约定。
·存储类型,这是Stata存储其数据的方式。就我们的目的而言,足以知道诸如strf之类的类型是字符串或文本变量,而此数据集中的所有其他类型都是数字。虽然此数据集中没有,但Stata也允许任意长的字符串或strL。 strLs还可以包含二进制信息。见[U] 12.4字符串。
·显示格式,控制Stata如何在表格中显示数据。参见[U] 12.5格式:控制数据的显示方式。
·值标签(可能)。这是允许Stata在显示文本时存储数值数据的机制。参见[Gsw] 9标签数据和[u] 12.6.3值标签。
·变量标签,在与其他人通信时称为变量。
正如我们将要看到的,Stata在制作表时使用变量标签。
数据集远不仅仅是它包含的数据。它也是使数据可供原始创建者以外的其他人使用的信息。
尽管描述数据告诉我们一些关于数据结构的信息,但它对数据本身几乎没有说明。可以通过单击统计信息>摘要,表和测试>摘要和描述性统计信息>摘要统计信息并单击确定按钮来汇总数据。您也可以在命令窗口中键入summary,然后按Enter键。结果是一个表,其中包含有关数据集中所有变量的摘要统计信息:
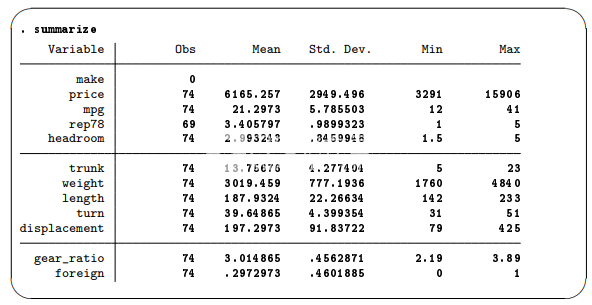
从这个简单的总结,我们可以了解一些数据。首先,价格与今天的汽车价格完全不同 - 当然,这些汽车现在都是古董。我们可以看到燃气里程并不是特别好。汽车爱好者可以感受到其他深奥的特征。
这里还有另外两个重要的项目:
·make变量列为没有观察结果。它实际上没有数值观察,因为它是一个字符串(文本)变量。
·rep78变量的观察值比其他数值变量少五个。这意味着rep78有五个缺失值。
虽然我们可以使用汇总和描述命令来获取数据集的鸟瞰图,但Stata有一个命令可以很好地深入描述变量的结构,内容和值:codebook命令。在命令窗口中键入代码簿并按Enter键或将菜单导航到数据>描述数据>描述数据内容(代码簿)
然后单击“确定”。查看输出,看看可以从这个简单的命令中学到很多东西。
如果需要,您可以在“结果”窗口中向后滚动以查看之前的结果。我们将重点关注make,rep78和foreign的输出。
为了开始我们的调查,我们想在一个变量上运行codebook命令,比如make。像往常一样,我们可以使用菜单或命令行来完成此操作。要通过菜单获取make的codebook输出,请首先导航到Data> Describe data> Describe data contents
(码本)。当对话框出现时,有多种方法可以告诉Stata只考虑make变量:
·我们可以在变量字段中键入make。
·“变量”字段是一个接受变量名称的组合框控件。单击“变量”字段右侧的下拉三角形可显示当前数据集中的变量列表。
在这种情况下,从列表中选择变量将在变量名称中输入变量名称。
更简单的解决方案是在命令窗口中键入codebook make,然后按Enter键。
结果提供了丰富的信息:

输出的第一行告诉我们变量名称(make)和变量标签(Make和Mode1)。
变量存储为字符串(这是另一种说“文本”的方式),最大长度为
18个字符,虽然只有17个字符的大小就足够了。所有值都是唯一的,因此如果需要,make可以用作观察的标识符 - 在将来自多个源的数据放在一起或尝试从数据集中清除错误时通常很有用。
没有缺失值,但是内部存在空白。如果我们期望make是一个单字串变量,那么后一个事实可能会有用。
语法注释:告诉codebook命令在make变量上运行是在Stata语法中使用varlist的一个例子。
软件无法下载?不知道解压密码?微信关注订阅号"闪电下载"获取
本帖长期更新最新版 请收藏下载!版权声明:本站提的序列号、注册码、注册机、破解补丁等均来自互联网,仅供学习交流之用,请在下载后24小时内删除。

















