
SIMCA14.1破解版是一款功能强大的数据统计分析软件。现在市面上的数据软件非常的多,这款工具则是您需要的唯一多变量工具。不管是多少数据它都能轻松快速的进行分析和掌控。再复杂的时间序列数据还是其他数据,都能够按需求转换为可视的信息,让用户能够方便的进行解释,并且根据提供的信息大胆的做出战略决策,避免盲目决策所带来的风险和失误。作为一个完美的多变量工具,只要您的数据成为可视信息,您就可以在简单的环境中轻松解释和决定数据。该软件的可靠性以及高速的数据处理使您可以轻松使用该软件来探索,分析和解释您的数据。SIMCA软件经过几十年的发展,现在已经是最受欢迎的多元变量统计分析软件。作为行业的标杆来有效的挖掘分析和探索您的数据,完美的解释数据结果,并拥有诸多功能模块,包括PCA、OPLS®、OPLS-DA®、O2PLS®等为您的工作提供最佳解决方案。本次小编带来最新破解版,含破解补丁,亲测可完美破解激活软件!
 二、批量数据分析
二、批量数据分析
安装破解教程
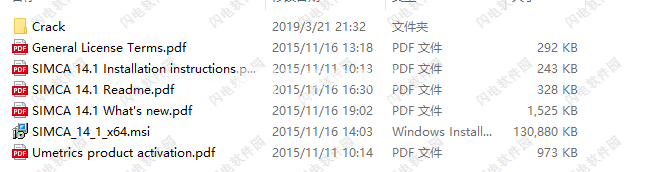
1、在本站下载并解压,如图所示,得到SIMCA_14_1_x64.msi安装程序和Crack破解文件夹,内含Patch.exe破解补丁
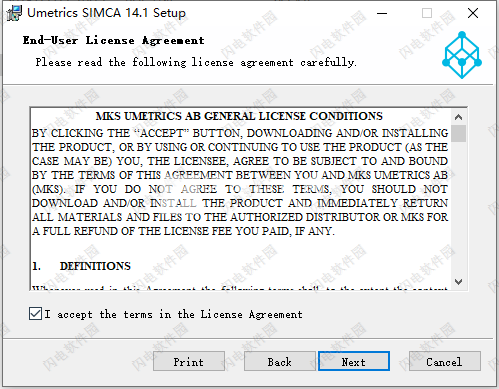
2、首先我们来安装软件,双击SIMCA_14_1_x64.msi开始安装,如图所示,勾选我接受许可证协议条款,继续点击next
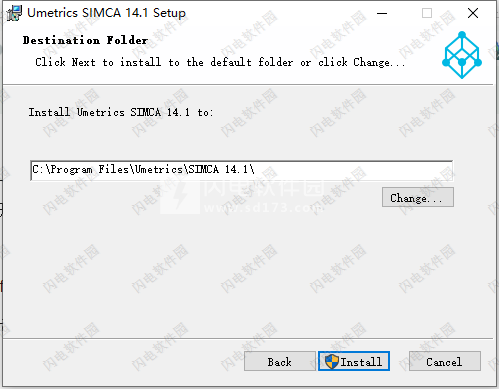
3、一路next,如图所示,选择软件安装路径,点击安装
4、安装完成,如图所示,去勾选运行软件选项,点击finish退出安装向导
5、然后我们将破解补丁复制到安装目录中,运行,点击patch按钮,出现ok字样退出补丁
SIMCA 14.1新版特色
一、SIMCA 14.1的新功能:
1、模型更新可能性
2、在SIMCA-online中使用更新SIMCA项目后显示的SIMCA-在线元数据。
3、补批批次级别模型,批次不在批次演化模型中
4、脚本功能o将向量导出到Python
o从Python导入向量
o批量级别数据集创建
o选定模型选项功能
o层次模型构建
o工作集滞后
o转换和扩展
二、SIMCA14.1是SIMCA 14的次要升级,包括:
1、在对齐时改进了比中位批次更短和更长的处理
2、应用“New as”时复制特定于相位的变量缩放
3、与以下相关的微小改进:oSIMCA导入批处理和阶段窗格o批处理数据的交叉验证组o $日期/时间格式成熟度的端点计算
o批量数据的EWMA计算
o EWMA过滤器
oBCC绘图工具选项卡选项显示所有批次
oBCC创建列表包括批次ID
o贡献图:由单变量偏差着色的变量
o由观察向量着色的光谱图颜色(类别)
o在批处理级别添加辅助ID的可能性
o已筛选数据集的命名约定注意:SIMCA 14.1文件不向后兼容S / MCA 14。
软件特色
1、通过与SIMCA-online无缝集成简化模型维护,更新模型
2、批量建模的灵活性;增强了自动化工作流程的功能
3、在SIMCA中使用您最喜欢的预处理 – 接近使用Python脚本进行预处理,转换和统计计算的无限可能性
4、通过SIMCA-online 14中的更新SIMCA项目功能快速有效地更新模型 – SIMCA 14.1仅与SIMCA-online 14兼容。
5、使用BEM和BLM以及分层模型的脚本自动构建模型
6、使用新批次补充现有模型,并自动重新创建所有数据集和模型,包括批次级别
7、高效的模型补充/更新功能;自动模型娱乐;仅在批次级别包含新批次
软件优势
1、您需要的唯一多变量工具
三十多年来,Sartorius Stedim Data Analytics AB帮助工程师,分析师和科学家使用SIMCA掌握他们的数据。无论是大量数据,批量数据,时间序列数据还是其他数据,SIMCA都会将您的数据转换为可视信息,以便于解释。这使您能够快速,自信地做出决策并采取行动。SIMCA将继续满足您现在和将来的数据分析需求。
2、探索 - 分析 - 解释
深入了解数据,使用多变量分析查找隐藏的详细信息。您可以使用直观的图形界面轻松查看趋势和群集。
SIMCA可帮助您分析过程变化,识别关键参数并预测最终产品质量。只需单击几下,您就可以了解过程状态。
借助SIMCA中包含的综合工具箱,您可以轻松地解释多变量模型的结果。
3、数据挖掘
SIMCA不仅可以帮助您提取有价值的信息,还可以对其进行构建,以便在数据中查找隐藏的详细信息。
4、流程建模
SIMCA使用OPLS和O2PLS处理复杂的过程数据并提取真实的预测信息。
5、互动图形
体验图形界面,使您能够轻松解释数据并做出正确的描述。
使用帮助
一、过程数据分析
对实际过程或系统的任何调查都基于测量(数据)。五十年前,测量设备昂贵而且很少,因此在过程中测量的数据量有限;这里的温度和压力,那里的流速。对这些少量数据的监控,显示和分析相对简单,一些运行的数据图表提供了有关过程状态的所有可用信息。
今天,传感器和在线仪器的电池以各种形式提供来自过程的所有部分的数据,通常以非常短的间隔。大量数据被输入计算机,重新计算成移动平均值(每分钟,每小时,每天,每周等)并显示和存储。
从几乎没有频繁测量的情况到许多几乎连续测量的变量的这种变化仍未影响过程数据的处理方式,可能导致大量信息丢失。通过适当的多变量分析方法,如主成分(PC)和潜在结构投影(PLS),以及最近的扩展OPLS和O2PLS,在SIMCA包中,大量的过程数据可以提供易于掌握的有关状态的图形信息过程,以及重要的过程变量集之间的关系。这些多变量方法可有效利用所有相关数据,几乎不会丢失信息。
1、 处理数据属性
1、 处理数据属性
在进入过程数据分析之前,讨论它们的性质可能是有用的。通常随着时间的推移定期测量数据;每天,每小时或每分钟说。对于不同变量,这些间隔通常是不同的。我们可以识别过程数据的五个类别,类型:受控过程变量,结果变量,原材料特征,中间结果变量和不受控制的变量。变量类型在下面的文本中描述。
2、受控制的过程变量
与过程条件的受控设置相关,这些变量原则上可以改变,从而影响过程的结果和输出。我们将用xik(观察i,变量k)表示这些变量的值。
这些变量的例子是:
T1,T2:反应器1和2中的测量温度。
P1,P2:反应器1和2中的压力。
f12:从反应器1到反应器2的流速。
3、结果变量
测量来自过程的产品的重要属性的多变量结果变量(输出,响应)的可用性极大地增加了更好地理解和优化过程的可能性。结果变量表示为yim(数据点i,y-变量m)。
这些变量的例子是:
yi1=主要产品的产量(%)。
yi2=杂质水平(%)。
yi3=副产品数量。1(%)。
yi4=产品的拉伸强度。
4、原料特性
原料(输入)的特征也用xik表示。这些变量通常对过程和产品属性非常重要,但通常很难或无法控制。
这些变量的例子是:
饲料中铁,煤,镍和钒的浓度。
输入纸浆中的纤维长度分布。
原料的气相色谱和光谱(NMR,IR等)分析。
5、中间结果变量
中间结果变量由xik,yim或zit表示。
这些变量的例子是:
反应器1的输出粘度(=输入反应器2)。
反应器1的输出中的氧浓度。
6、不受控制的变量
不受控制的变量用xik或zit表示。
这些变量的例子是:
空气湿度,冷却水温度。
喷射氮气中的氧气量。
衡量流程及其输入和环境数据的目的是:
提供信息,以便更好地了解过程,过程的不同部分之间的关系,反应器内发生的化学反应或其他反应等。
产生关于过程“状态”的信息,识别趋势,特性等,以使过程保持在适当的控制之下。
了解输出如何受过程和输入变量的影响,以提高产品质量,降低制造成本,污染等。
对于批处理,K个变量以N个批次定期测量。这给出了每个批次的J×K矩阵(J个时间点(X)乘以K个变量)。因此,一组N个正常批次给出三维矩阵(N×J×K)。
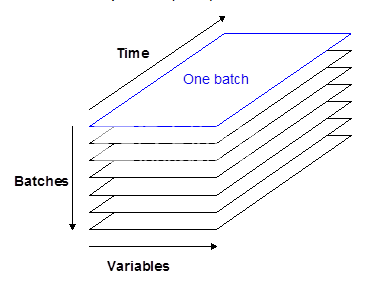
图1:历史数据的三向表,例如,具有J个时间点的N个批次和K个变量。批次通常具有不同的长度(图中未示出)并且也可以分阶段划分。
1、批量数据属性
1、批量数据属性
批处理数据和过程数据之间的差异之一是批处理具有有限的持续时间。每批产品在完成前也可以经历几个阶段。
由于批处理数据是批量收集的,因此在导入之前需要重新组织。
2、导入前重组3D表格
为了能够导入数据集,必须展开3向数据表以保留K变量的方向(参见图2)。得到的矩阵具有nobs=N×J个观测值(行)和K个列。因此,这个矩阵X将个体观察作为一个单元,而不是整个批次。
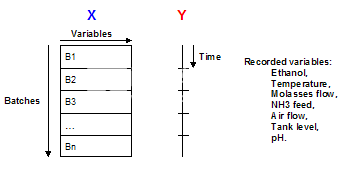
图2.图1的三向矩阵沿批处理方向展开,得到一个N×J行和K列的双向矩阵。每行具有来自单批次观察的数据(xijk)(批次i,时间j,变量k)。
3、传统数据分析:一次一个或两个变量
3、传统数据分析:一次一个或两个变量
为了深入了解过程的状态,通常会显示重要变量及其随时间的变化(图3)。这适用于最多5到10个变量,但此后变得越来越难以理解。此外,这些“时间痕迹”几乎没有揭示不同变量之间的关系。

图3.两个变量在水平轴上相对于时间绘制。
变量对的散点图是时间轨迹的常见补充(图4)。人们希望识别相关性,从而识别导致输出变量变化的重要过程变量。
成对散点图的基本问题是它们提供的信息很少,一方面是输入和过程变量之间的真实关系,另一方面是输出变量之间的真实关系。这是因为输出(y)受输入和过程变量(x)的组合的影响。
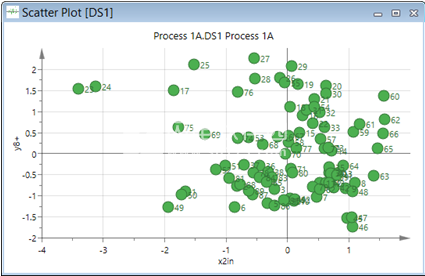
图4.y8*(杂质)对x2in(其中一个输入)的散点图。
三、多变量方法
三、多变量方法
使用多变量方法,可以研究单个上下文中所有变量之间的关系。这些关系可以在图中显示,因为它们易于理解为时间轨迹和成对散点图。
SIMCA中包含的多变量过程数据分析方法包括PC分析和建模,PLS建模,OPLS建模,O2PLS建模等。拟合方法的原理和数学将在后面的简介中进行简要介绍,并在统计附录中进行更详细的介绍。还参考了其他相关文献。
在这里,我们将指出如何使用这些方法来解决过程数据分析中的典型问题。
1、总结一组过程变量
在进程上测量的数据通常存储在某种数据库中。包含N个数据点的K个变量值的过程数据库可以被视为表格,矩阵。我们用X表示整个表。表中的每一列对应一个变量(xk),一行(xi)对应于在一个时间点观察到的值。
输入或输出或两者都可以在多变量控制图中显示。
2、总结批次数据
批量测量的数据通常也存储在某种数据库中。批处理数据和过程数据之间的差异之一是批处理具有有限的持续时间。每批产品在完成前也可以经历几个阶段。
输入或输出可以在批生产控制图表中显示。
3、PCA-主成分分析
数据表的主成分分析给出得分的向量,其值为tia,其总结了进入分析的所有变量。习惯上计算两个或三个评分向量,然后将它们相互绘制(tt-plot)。这给出了一张图片,它是过程行为随时间变化的最佳总结!在这个情节中,我们可以看到趋势,不寻常的行为和其他感兴趣的事物。根据经验,人们将能够识别该PC得分图中的区域,其中该过程保持在“正常”操作下,从而提供多变量控制图。
得分图与加载图相结合,表明偏离正常操作的负责变量。
PCA还提供数据和PC模型之间的残差,偏差,名为DModX。当这些残差很大时,这表示该过程中的异常行为。为了看到这一点,我们绘制了剩余标准偏差DModX(残余距离,均方根)的图。
DModX大于DCrit的观察结果是异常值。当DModX是DCrit的两倍时,它们是强异常值。这表明这些观察结果与关于变量的相关结构的正常观察结果不同。
4、PLS-潜在结构的偏最小二乘投影
将结果变量与输入和过程变量相关联
常见的问题是“过程诊断”。这意味着识别那些对输出变量,结果变量Y的变化“负责”的输入和过程变量X.为此,人们经常尝试使用多元回归,但这会导致很大的困难,因为过程数据通常不具备回归建模的正确“属性”。特别是,回归分别处理每个结果变量(ym),因此最终得到一组模型,每个模型对应一个感兴趣的输出。这使得解释和优化变得困难或不可能。
为了严格解释“因果关系”,应使用统计设计(使用MODDE等软件)仔细进行数据收集。在流程日志中搜索输入和输出之间的关系是有风险的,而且往往不太成功。这是因为当在小的“控制间隔”内很好地控制重要因素时,过程不提供具有良好信息内容的数据。
PLS-分数
PLS建模已经针对这种情况明确开发,具有许多通常相关的输入和过程变量以及几个到多个结果变量。一个只是指定数据库中哪些变量是预测变量(X),哪些变量是相关的(Y),PLS找到两组变量之间的关系。
对于一组PLS模型维度,PLS模型表示为一组X得分向量,Y得分向量,X加权和Y加权向量。每个维度(索引a)表示X得分向量(ta)和Y得分向量(ua)之间的线性关系。每个模型维度的权重向量表示如何组合X变量以形成ta,并且将Y变量组合以形成ua。通过这种方式,数据被建模为X和Y中的一组“因子”及其关系。分数和权重的图表有助于模型解释。
PLS-装载
PLS分析产生变量的模型系数,称为PLS权重或负载。表示为w的X变量的加载表示这些变量的重要性,它们“在相对意义上”参与Y的建模的程度.Y变量的加载,用c表示,表示哪个Y-变量在相应的PLS模型维度中建模。
当这些系数绘制在w*c图中时,我们得到一张图片,显示X和Y之间的关系,那些重要的X变量,哪些Y变量与哪个X相关,等等。
PLS-残留物
类似于PC,PLS在Y侧和X侧都提供残差。这些(残余距离)的标准偏差可以与PCA一样绘制,以给出第三个“SPC”图(统计过程控制),显示该过程在DModX和DModY图中是否正常运行。
5、OPLS和O2PLS-正交偏最小二乘法
OPLS是PLS的扩展,解决了回归问题。OPLS将X的系统变化分为两部分,一部分与Y相关(预测),另一部分与Y不相关(正交)。这提高了模型的可解释性。在单Y情况下,只有一个预测分量,超出第一个分量的所有分量都反映了正交变化。但是,对于多个Y变量,可以有多个预测OPLS组件。
O2PLS是PLS的另一个扩展,解决了数据集成问题。因此,在双块(X/Y)上下文中,O2PLS检查哪些信息在两个数据表之间重叠,哪些信息对于特定数据表(X或Y)是唯一的。O2PLS通过包含三种类型组件的灵活模型结构来完成此任务,即
(i)表示联合X/Y信息重叠的组件,
(ii)表达X的独特成分的组分
(iii)表达Y独有的成分。
对于OPLS和O2PLS,不同的组件可以通常的方式解释,因为保留了具有熟悉含义的分数,加载和基于残差的参数。
软件无法下载?不知道解压密码?微信关注订阅号"闪电下载"获取
本帖长期更新最新版 请收藏下载!版权声明:本站提的序列号、注册码、注册机、破解补丁等均来自互联网,仅供学习交流之用,请在下载后24小时内删除。

















